Matano now automatically runs Iceberg table maintenance on Matano tables, including data compaction and expiring snapshots, greatly improving query performance and cost efficiency. Read on for how table maintenance works and how we run completely serverless Iceberg table maintenance on AWS.

What's new
Matano will now run Iceberg table maintenance automatically in the background for all Matano Iceberg tables. This requires no manual intervention and will greatly improve the performance of your queries and overall cost efficiency by compacting data into large files and minimizing metadata files.
How it works
Iceberg Table maintenance
Iceberg provides table maintenance procedures out of the box that allow performing powerful table optimizations. Especially when data is produced by streaming systems like Matano, files may be of a small size relative to the total data size. This hurts query performance, as engines have to scan many small files. Compaction refers to the process of rewriting many small files into larger data files. Due to Iceberg's snapshot isolation, in a streaming system, each write to a table will create a new snapshot. Over time, this results in many snapshots. Iceberg offers an Expire snapshots maintenance task that allows you to retain a subset of recent snapshot and expire older snapshots. Expiring snapshots deletes any manifest lists, manifests, and data files associated with the expired snapshots.
For more on Iceberg table maintenance, refer to these excellent blog posts.
Implementing table maintenance
Practically, Iceberg offers maintenance tasks through the official Java API and associated Spark actions. Some of Matano's core tenets are that maintaining high cost efficiency and a completely serverless experience, meaning you never have to run or maintain any servers.
Keeping this in mind, for compaction, we can rely on Amazon Athena. Athena provides an OPTIMIZE table REWRITE DATA command that runs Iceberg compaction on a table. We orchestrate table compaction using an AWS Step Functions state machine that is triggered hourly by an CloudWatch event rule (as Matano tables are partitioned hourly) and runs an Athena query to optimize the previous partition hour's data.
Visually, it looks something like:
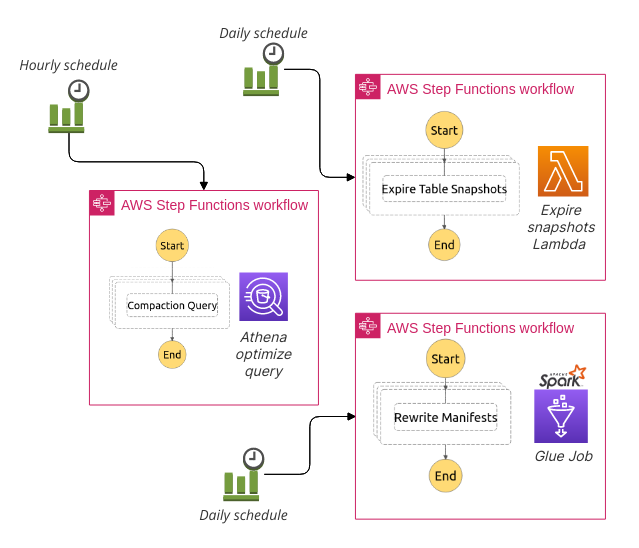
For expiring snapshots, we use the Iceberg Java API directly. We implement a Lambda function triggered daily on a CloudWatch event rule that expires the snapshots older than a day. You may be suprised at the choice of Iceberg table operations in a Lambda function, but the expire snapshots task is a purely IO bound operation that scans and deletes S3 files, so the CPU/memory limitations of a Lambda function are not relevant.
The entire system is highly cost efficient and runs smoothly in the background without requiring any servers to maintain.
Get started
You can reap the benefits of automatic Iceberg table maintenance in Matano today without making any changes.